
이번 단원에서는
- CPU scheduling algorithms
- scheduling 기준
- multiprocessor와 multicore scheduling
- real-time scheduling algorithms
- Windows, Linux, 그리고 Solaris operating system
- CPU scheduling algorithms을 모델링하고 simulate
- 몇몇 다른 CPU scheduling algorithm
CPU Schdeuling basic concepts
CPU는 한 순간에 하나의 프로세스만을 실행함. 만약 CPU가 한 프로세스의 실행을 끝내고 다음 프로세스를 고르려면 어떤 프로세스를 선택해야하는 것인가? 이때 CPU schdeuling을 통해 CPU가 다음에 수행할 프로세스의 순서를 정하게 됨!!
CPU-I/O Burst Cycle
각각 CPU가 사용하는 시간, I/O가 사용하는 시간을 나타냄
프로세스의 실행이 CPU execution과 I/O 대기의 사이클로 구성되는데, 프로세스들은 CPU가 프로세스를 실행하는 상태와 입/출력을 위한 상태를 교대로 왔다갔다함
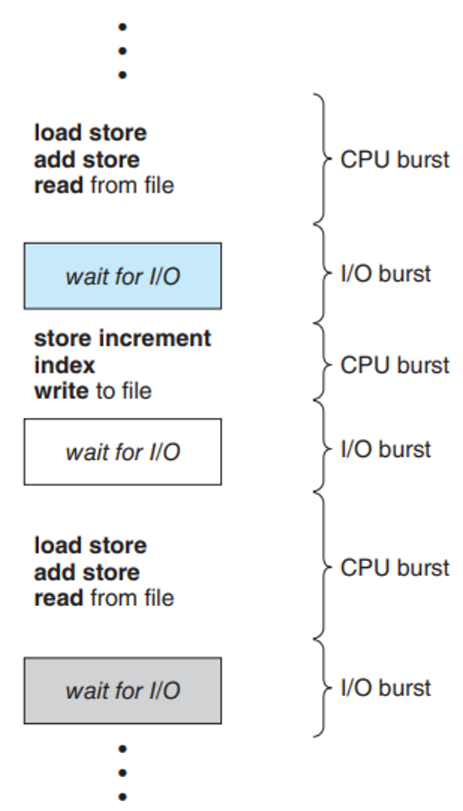
지금 이 그림에서, CPU burst는 프로세스의 명령어를 수행하는 상태, I/O burst는 프로세스가 입력이나 출력을 하는 상태임!
- I/O bound program은 짧은 CPU burst를 자주 가짐
- CPU bound program은 긴 CPU burst을 가짐
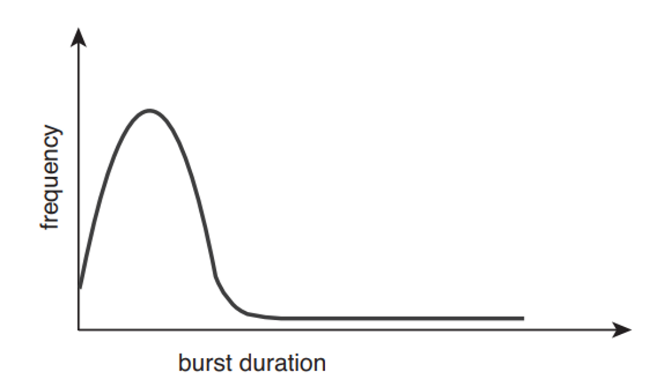
이게 burst 지속 시간에 따른 입/출력의 빈도수를 표현한 것임
CPU Scheduler
말그대로 CPU가 idle일 때마다, ready queue에 있는 process를 CPU에 할당시키는 것이다.
Preemptive Scheduling, Non-Preemptive Scheduling
- process의 4가지 상황에 따라 CPU scheduling 결정
- running → waiting (ex. 입/출력 요청)
- running → ready (ex. 다른 프로세스의 interrupt 발생)
- waiting → ready (ex. 입/출력의 종료)
- terminates
- Preemptive scheduling: CPU가 현재 프로세스를 실행 중일때, 스케줄러에 의해 현재 프로세스의 CPU 제어권을 다른 프로세스한테 넘기는 스케줄링
- Non-preemptive scheduling: CPU가 현재 실행중인 프로세스가 완료될때까지 다른 프로세스들은 대기하는 스케줄링
Dispatcher
CPU의 제어를 스케줄러가 선택한 프로세스에게 주는 모듈!이다.
어떤 기능을 담당하냐면,
- Context Switching
- Switching to user mode
- 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동
Dispatch latency란 무엇인가.? dispatcher가 하나의 process를 정지하고 다른 process의 수행을 시작하는 데까지 소요되는 시간! 당연히 짧을수록 좋다.
linux에서 vmstat 1 3 를 통해 1초동안 context switching의 평균 빈도를 알 수 있다. 그리고 cat /proc/2166/status 를 통해 pid=2166에 대해 통계자료를 볼 수 있다.
Scheduling Criteria
CPU scheduling 알고리즘을 비교하기 위한 여러가지 기준이 있다.
CPU utilization
- CPU의 이용률
- 0~100%, 실제 시스템 상으로는 40~90%가 good
Throughput
- 단위시간 당 완료된 process의 개수
Turnaround Time
- process의 제출 시간과 완료 시간의 간격
- 메모리에 들어가기 이해 기다리며 소비한시간 + ready queue에서 대기한 시간 + CPU에서 실행하는 시간 + 입/출력 시간
Waiting Time
- ready queue에서 대기하는 시간
- scheduling algorithm에 영향 받음
Response Time
- 하나의 request를 제출한 후, 첫번째 response가 나올 때 까지의 시간
그래서 이 CPU scheduling을 통해 우리가 이루고자 하는 것은?
- maximize CPU utilization and throughput
- minimize turnaround time, waiting time, and response time
CPU scheduling에 대해 optimization도 한다.
보통 척도들을 두루두루 만족시키는 것이 좋겠지만, 상황에 따라 특정 척도를 만족시키는 것이 우선시 될 수도 있음!
Scheduling Algorithms
그러면 이제 본격적으로 Scheduling algorithms에 대해 알아보자. 그전에 먼저 3가지 가정을 한다.
- process당 한 개의 CPU burst만 존재한다.
- average waiting time을 비교한다.
- 하나의 processing core만 이용한다.
First-Come, First-Served Scheduling
- 가장 간단하다. FIFO queue를 이용하여 먼저 요청하는 process가 CPU를 할당받는다.
- Non-preemptive 방식이다.
- 하지만 문제점이 있다. CPU를 오래 사용하는 하나의 process가 있으면, average waiting time이 매우 길어진다. → Convoy EffectProcess Burst Time
P1 24 P2 3 P3 3
만약 P1→P2→P3가 순서대로 도착한다면 다음과 같은 방식으로 스케줄링한다. 이때의 avg waiting time: 17이다

만약 P2→P3→P1 순으로 도착한다면 avg waiting time: 3으로 줄어든다.

Shortest-Job-First Scheduling
- FCFS 방식을 개선하였다.
- 현재 남아있는 burst time 기준으로 가장 짧은 process에게 할당한다. 이때 남아있는 burst time이 같다면, FCFS scheduling을 적용한다.

이렇게 process들이 있을 때,

이렇게 수행한다!
FCFS 방식과 비교해보면, avg waiting time(SJF): 7, avg waiting time(FCFS) : 10.25이다.
- 근데 한가지 문제점이 있다. 다음 CPU burst가 얼마일지 알 수 없다. 그래서, 우리는 next CPU의 burst가 과거의 것과 비슷할 것이라고 가정하고 예측을 수행한다. 예측을 수행할 때, 이전 CPU burst의 값을 저장해놓고 exponential average를 이용하여 예측한다. 그 식은 다음과 같다.
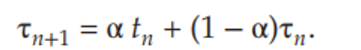
- 알파는 확률, tn은 n번쨰 CPU 버스트의 길이를 뜻한다. 타우n은 n시점까지의 과거 기록을 저장한다.
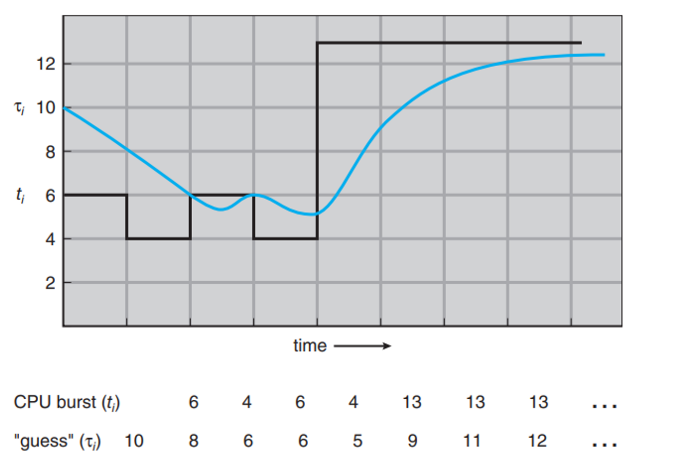
- 그래프로 표현하면 다음과 같이 표현할 수 있다. 완전 동일하지 않더라고 대략 비슷하게 예측하는 것을 확인할 수 있다.
- 그리고 Preemptive방식도 있고, Non-preemptive 방식도 있다.
Round-Robin Scheduling
- FCFS와 유사하지만, 프로세스들 사이를 옮겨다니기 위해서 preemptive가 추가된 scheduling이다. 즉, process사이의 context switching이 가능할 때만 RR방식을 이용한다.
- Time quantam(time slice) 라고 하는 시간을 할당량을 10~100ms정도 정의한다.
- ready queue는 원형으로 동작한다.
RR에는 두 가지 경우가 존재하는데
- process의 CPU burst가 TQ보다 짧은 경우
- process가 셀프로 CPU를 방출
- scheduler는 ready queue에 있던 다음 process를 진행
- process의 CPU burst가 TQ보다 긴 경우
- 시간초과되면 OS에서 interrupt
- Context switching
- 실행하던 process는 ready queue의 tail로 가서 다시 순서를 기다린다.

이렇게 실행된다. RR의 경우, average waiting time을 줄인다는 장점이 있다.
근데, Time quantum 설정이 중요하다. 너무 커도 안되고, 작아도 안 된다.
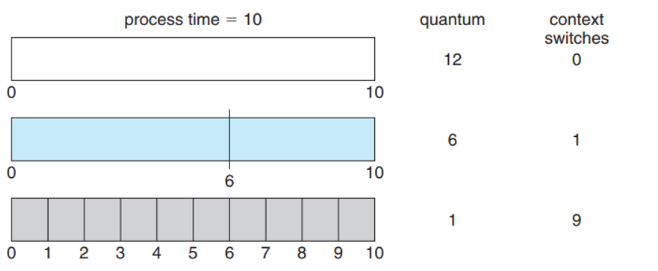
context switching시간보다 time quantum이 더 적다면 process가 아예 수행되지 않는다!! Turnaround 입장에서는 TQ가 큰게 좋고, reponse time 입장에서는 TQ가 작은게 좋다.
Priority Scheduling
priority는 우선순위가 가장 높은 process에게 CPU 권한을 할당한다.

preemptive, nonpreemptive 방식 둘 다 가능하다.
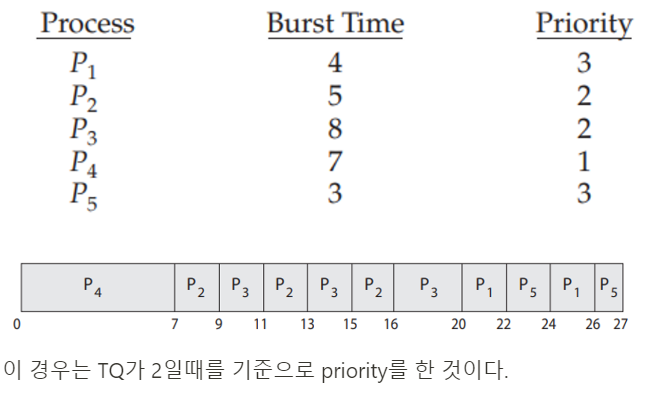
근데 문제점이 있다. 우선순위가 낮은 process는 계쏙해서 밀린다. 그리고 우선순위가 같으면 RR 병행한다.
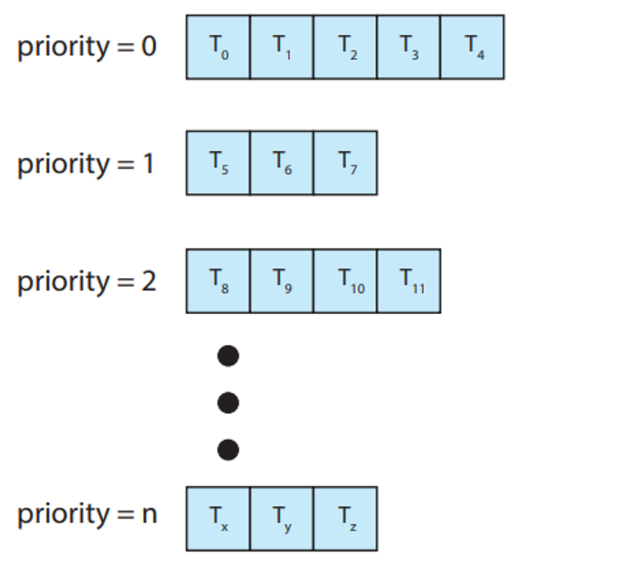
Multilevel Queue Scheduling
multiple queue를 이용하여 multi level schedulig을 한다. 그러니까, ready queue를 다수의 별도 queue로 분류하여 수행하는 방식이다.
그래서 queue사이의 scheduling과 각 queue간의 scheduling이 둘 다 있다.
각각의 queue 내부에서는 RR을 쓸 수도, FCFS를 쓸 수도 있다.
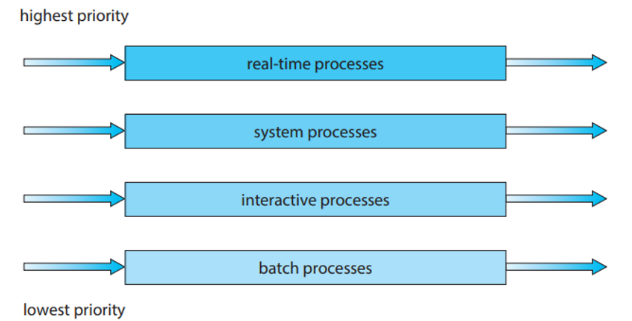
이 위에있는 건, priority queue보다도 절대적인 우선순위를 가진다. real-time process, system process의 queue가 비어있지 않는 이상, interactive process는 실행될 수 없다. 뭐 이런식?
Multilevel Feedback Queue Scheduling
일단 multilevel queue에서는 process의 queue간 이동이 불가능했었다.
근데 여기서는 process들을 CPU burst 성격에 따라 구분한다. 어떤 프로세스가 CPU 시간을 너무 많이 사용하면, 낮은 우선순위의 큐로 이동되고, 입/출력 중심 프로세스와 대화형 프로세스들을 높은 우선순위 큐로 이동시킨다. 만약에 낮은 우선순위의 큐에서 너무 오래 대기하는 프로세스가 있다면, 높은 우선순위의 큐로 이동시킨다.
multilevel feedback queue scheduling은 다양한 parameter가 있다.
Thread Scheduling
이번에는 thread를 중심으로 scheduling을 살펴보자. user-level과 kernel-level thread의 차이는 어떻게 스케줄 되느냐에 있다. Many-to-one과 many-to-many 모델을 구현
Contention Scope(경쟁범위)
- Process-contention scope(PCS):
Many-to-one과 many-to-many 모델을 구현하는 시스템에서, thread library가 user-level thread를 가용한 LWP(Light Weight Process)상에서 스케줄링을 함.
이 구조는 동일한 process에 속한 thread 사이에서 CPU를 경쟁함
즉, user-level thread는 thread library가 사용이 가능한 LWP에 user-level thread를 schduling하는 것이고, PCS는 동일한 프로세스 범위에서 process 내부의 thread들이 CPU를 할당받기 위해 경쟁하는 것이다.
- System-contention scope(SCS):
실제로 CPU 상에서 실행되기 위해서, OS가 kernel thread를 물리적인 CPU로 스켖루링 하는 것이 필요함.
CPU상에 어떤 kernel thread를 스케줄하기 위해 결정하기 위해서 SCS를 사용함@!
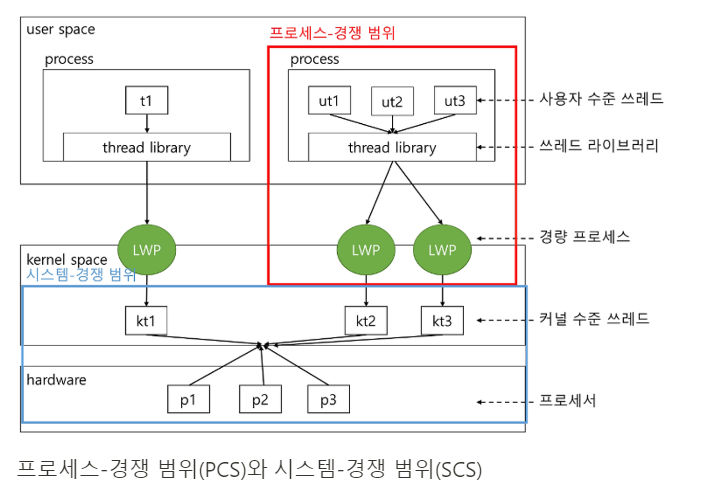
Pthread Scheduling
- PTHREAD_SCOPE_PROCESS: PCS scheduling을 사용하여 thread scheduling
- PTHREAD_SCOPE_SYSTEM: SCS scheduling을 사용하여 thread scheduling
#include <pthread.h>
#include <stdio.h>
#define NUM THREADS 5
int main(int argc, char *argv[])
{
int i, scope;
pthread t tid[NUM THREADS];
pthread attr t attr;
/* get the default attributes */
pthread attr init(&attr);
/* first inquire on the current scope */
if (pthread attr getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope∖n");
else {
if (scope == PTHREAD SCOPE PROCESS)
printf("PTHREAD SCOPE PROCESS");
else if (scope == PTHREAD SCOPE SYSTEM)
printf("PTHREAD SCOPE SYSTEM");
else
fprintf(stderr, "Illegal scope value.∖n");
}
/* set the scheduling algorithm to PCS or SCS */
pthread attr setscope(&attr, PTHREAD SCOPE SYSTEM);
/* create the threads */
for (i = 0; i < NUM THREADS; i++)
pthread create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM THREADS; i++)
pthread join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread exit(0);
}
Multiprocessor Scheduling
multiprocessor는 아무래도 multi이다보니 schedulig이 더 복잡하다. Multiprocessor scheduling은 2가지 방법이 존재한다.
Multicore Precessors
- Asymmetric Multiprocessing
하나의 processor를 일명 master server로 지정하고, 모든 스케줄링 결과, 입/출력 처리, 다른 시스템 이동을 관리한다. 그리고 나머지 processor들은 그냥 user code만을 수행한다.
자료공유의 필요성을 배제하기 때문에 간단하다. 근데 master server에 시스템 부하 올 수도?
- Symmetric multiprocessing(SMP)
각각의 processor가 self-scheduling을 한다.! 여기서도 두개의 전략이 나뉘는데,
- 모든 thread가 ready queue 공통으로 사용→ possible race condition
- 각각의 proessor가 독립적인 ready queue → load balancing algorithm
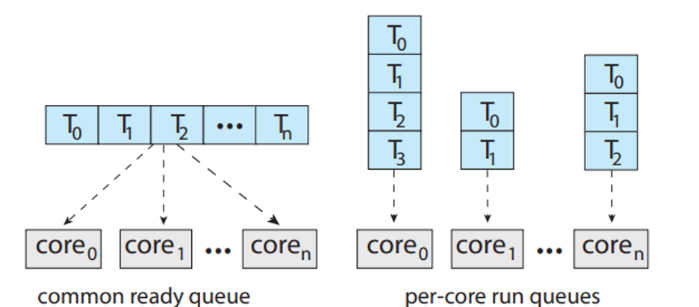
다만 주의 할 점은 여러개의 processor가 공통 자료구조에 접근하여 갱신하면 스케줄러는 신중하게 프로그램되어야 하고,
두 processor가 같은 process를 선택하지 않도록 해야하고,
process 들이 queue에서 사라지지 않도록 보장해야 한다.
SMP system을 가진 multicore processor는 multichip에 비해 빠르고, power를 덜 소비한다.
memory stall:
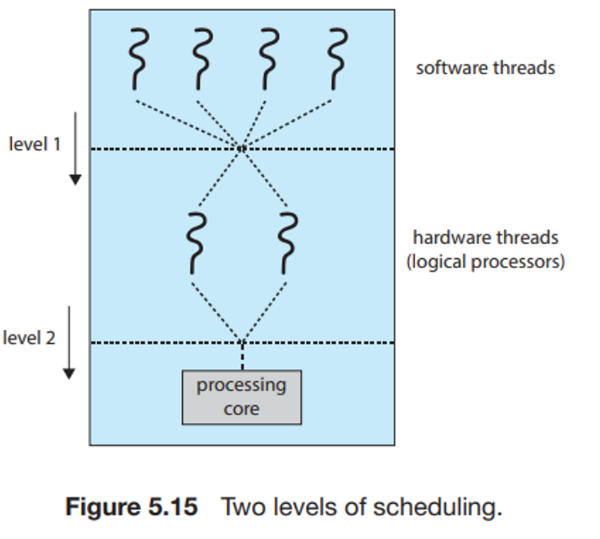
multithreaded processing cores:
이 부분은 잘 이해가 안 가니까 다시 보자. 일단 그림만 첨부해놓겠따.
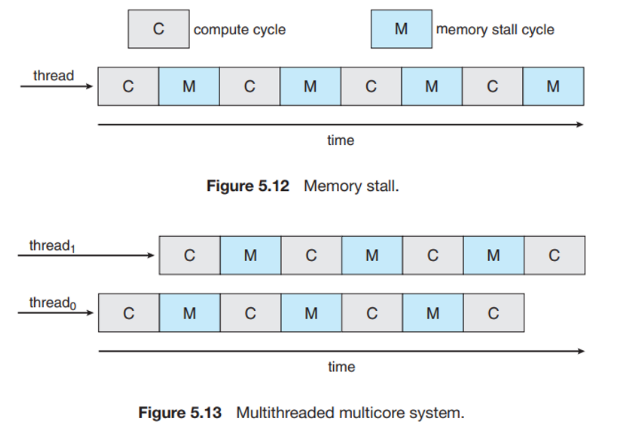
chip multithreading(CMT) : 하드웨어적으로 여러개의 thread를 실행할 수 있도록 하는 것
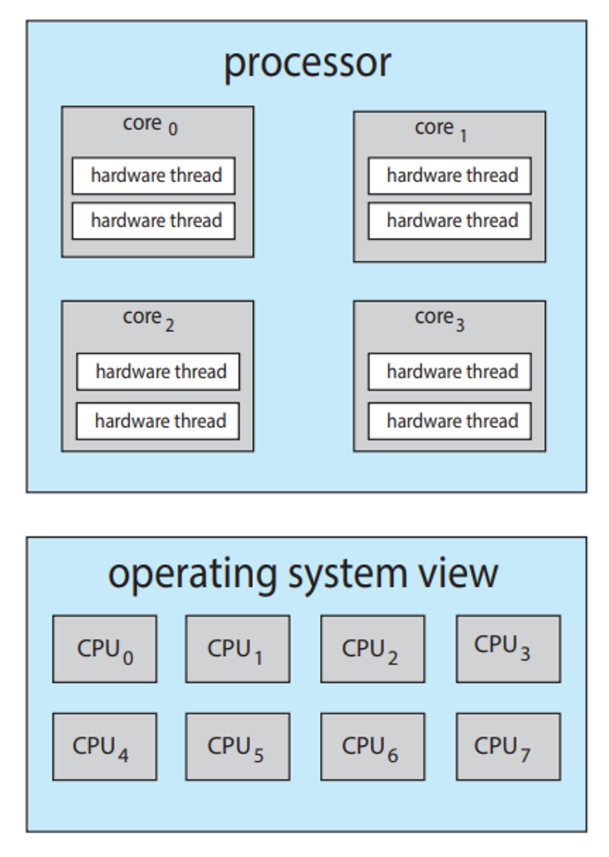
이거 보면 process는 4개의 core에 thread가 각 2개씩 있는 거지만, OS 관점에서는 8개의 core로 보인다!!!!!
- 하나의 core에서 multithreading을 하는거
- Coarse grained: long-latency event가 발생할 떄 까지 실행
- Pipeline flushing → high cost of thread switching
- Fine-grained(interleaved): instruction cycle 단위로 switching함
- Concurrent, not parallel
- holding multiple threads
- sharing hardware for execution
- two levels of scheduling
- share-aware algorithm(동시에 실행해야할 thread들은 서로 다른 core에 할당)
- Concurrent, not parallel
- No pipeline flushing → small cost; extra logic required
Load Balancing
SMP 시스템의 모든 processor사이에 workload가 고르게 배분되도록 시도하는 것! 두가지 방식이 존재한다.
- Push migration
특정 task가 주기적으로 processor의 workload를 검사하고, 만일 불균형한 상태라면 workload가 적은 처리기로 process를 push하여 workload를 분배하는 방식
- Pull migration
ide한 processor가 직접 waiting task를 가져오는 방식
Balanced load를 위해서는 모든 queue의 thread수를 비슷하게 유지하거나 또는, 모든 queue에 동등한 priority를 부여하는 것이 있따.
Processor Affinity
SMP 시스템이 processor간 migration을 피하고 대신 같은 processor에서 process를 실행시키려고 하는 현상이다.
processor affinity가 왜 발생하는가?
만약에 processor간의 migration이 발생하면, cache memory를 삭제하고, migrate한 processor에 다시 cache memory를 작성하게 되는데, 이 작업이 비용이 많이 든다.
processor affinity도 두가지 종료가 있다.
- Soft Affinity: 동일한 Processor에서 process를 실행시키려고 노력하는 정책을 가지고 있지만 보장하지는 않음
- Hard Affinity: system call을 이용해 실행할 수 있는부분집합 processor를 만들어놓고, 그 안에서 process를 할당함
<aside> ▶️ Load balancing과 processor affinity 사이에 counteraction이 존재함!!
</aside>
HMP(Heterogeneous Multiprocessing)
'OS' 카테고리의 다른 글
| [운영체제] Threads & Concurrency (2) (1) | 2024.04.18 |
|---|---|
| [운영체제] Threads & Concurrency (0) | 2024.04.11 |
| [운영체제] Processes(2) (2) | 2024.04.03 |
| [운영체제] Processes (0) | 2024.04.01 |
| [운영체제] OS 구조 (0) | 2024.04.01 |
이번 단원에서는
- CPU scheduling algorithms
- scheduling 기준
- multiprocessor와 multicore scheduling
- real-time scheduling algorithms
- Windows, Linux, 그리고 Solaris operating system
- CPU scheduling algorithms을 모델링하고 simulate
- 몇몇 다른 CPU scheduling algorithm
CPU Schdeuling basic concepts
CPU는 한 순간에 하나의 프로세스만을 실행함. 만약 CPU가 한 프로세스의 실행을 끝내고 다음 프로세스를 고르려면 어떤 프로세스를 선택해야하는 것인가? 이때 CPU schdeuling을 통해 CPU가 다음에 수행할 프로세스의 순서를 정하게 됨!!
CPU-I/O Burst Cycle
각각 CPU가 사용하는 시간, I/O가 사용하는 시간을 나타냄
프로세스의 실행이 CPU execution과 I/O 대기의 사이클로 구성되는데, 프로세스들은 CPU가 프로세스를 실행하는 상태와 입/출력을 위한 상태를 교대로 왔다갔다함
지금 이 그림에서, CPU burst는 프로세스의 명령어를 수행하는 상태, I/O burst는 프로세스가 입력이나 출력을 하는 상태임!
- I/O bound program은 짧은 CPU burst를 자주 가짐
- CPU bound program은 긴 CPU burst을 가짐
이게 burst 지속 시간에 따른 입/출력의 빈도수를 표현한 것임
CPU Scheduler
말그대로 CPU가 idle일 때마다, ready queue에 있는 process를 CPU에 할당시키는 것이다.
Preemptive Scheduling, Non-Preemptive Scheduling
- process의 4가지 상황에 따라 CPU scheduling 결정
- running → waiting (ex. 입/출력 요청)
- running → ready (ex. 다른 프로세스의 interrupt 발생)
- waiting → ready (ex. 입/출력의 종료)
- terminates
- Preemptive scheduling: CPU가 현재 프로세스를 실행 중일때, 스케줄러에 의해 현재 프로세스의 CPU 제어권을 다른 프로세스한테 넘기는 스케줄링
- Non-preemptive scheduling: CPU가 현재 실행중인 프로세스가 완료될때까지 다른 프로세스들은 대기하는 스케줄링
Dispatcher
CPU의 제어를 스케줄러가 선택한 프로세스에게 주는 모듈!이다.
어떤 기능을 담당하냐면,
- Context Switching
- Switching to user mode
- 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동
Dispatch latency란 무엇인가.? dispatcher가 하나의 process를 정지하고 다른 process의 수행을 시작하는 데까지 소요되는 시간! 당연히 짧을수록 좋다.
linux에서 vmstat 1 3 를 통해 1초동안 context switching의 평균 빈도를 알 수 있다. 그리고 cat /proc/2166/status 를 통해 pid=2166에 대해 통계자료를 볼 수 있다.
Scheduling Criteria
CPU scheduling 알고리즘을 비교하기 위한 여러가지 기준이 있다.
CPU utilization
- CPU의 이용률
- 0~100%, 실제 시스템 상으로는 40~90%가 good
Throughput
- 단위시간 당 완료된 process의 개수
Turnaround Time
- process의 제출 시간과 완료 시간의 간격
- 메모리에 들어가기 이해 기다리며 소비한시간 + ready queue에서 대기한 시간 + CPU에서 실행하는 시간 + 입/출력 시간
Waiting Time
- ready queue에서 대기하는 시간
- scheduling algorithm에 영향 받음
Response Time
- 하나의 request를 제출한 후, 첫번째 response가 나올 때 까지의 시간
그래서 이 CPU scheduling을 통해 우리가 이루고자 하는 것은?
- maximize CPU utilization and throughput
- minimize turnaround time, waiting time, and response time
CPU scheduling에 대해 optimization도 한다.
보통 척도들을 두루두루 만족시키는 것이 좋겠지만, 상황에 따라 특정 척도를 만족시키는 것이 우선시 될 수도 있음!
Scheduling Algorithms
그러면 이제 본격적으로 Scheduling algorithms에 대해 알아보자. 그전에 먼저 3가지 가정을 한다.
- process당 한 개의 CPU burst만 존재한다.
- average waiting time을 비교한다.
- 하나의 processing core만 이용한다.
First-Come, First-Served Scheduling
- 가장 간단하다. FIFO queue를 이용하여 먼저 요청하는 process가 CPU를 할당받는다.
- Non-preemptive 방식이다.
- 하지만 문제점이 있다. CPU를 오래 사용하는 하나의 process가 있으면, average waiting time이 매우 길어진다. → Convoy EffectProcess Burst Time
P1 24 P2 3 P3 3
만약 P1→P2→P3가 순서대로 도착한다면 다음과 같은 방식으로 스케줄링한다. 이때의 avg waiting time: 17이다
만약 P2→P3→P1 순으로 도착한다면 avg waiting time: 3으로 줄어든다.
Shortest-Job-First Scheduling
- FCFS 방식을 개선하였다.
- 현재 남아있는 burst time 기준으로 가장 짧은 process에게 할당한다. 이때 남아있는 burst time이 같다면, FCFS scheduling을 적용한다.
이렇게 process들이 있을 때,
이렇게 수행한다!
FCFS 방식과 비교해보면, avg waiting time(SJF): 7, avg waiting time(FCFS) : 10.25이다.
- 근데 한가지 문제점이 있다. 다음 CPU burst가 얼마일지 알 수 없다. 그래서, 우리는 next CPU의 burst가 과거의 것과 비슷할 것이라고 가정하고 예측을 수행한다. 예측을 수행할 때, 이전 CPU burst의 값을 저장해놓고 exponential average를 이용하여 예측한다. 그 식은 다음과 같다.
- 알파는 확률, tn은 n번쨰 CPU 버스트의 길이를 뜻한다. 타우n은 n시점까지의 과거 기록을 저장한다.
- 그래프로 표현하면 다음과 같이 표현할 수 있다. 완전 동일하지 않더라고 대략 비슷하게 예측하는 것을 확인할 수 있다.
- 그리고 Preemptive방식도 있고, Non-preemptive 방식도 있다.
Round-Robin Scheduling
- FCFS와 유사하지만, 프로세스들 사이를 옮겨다니기 위해서 preemptive가 추가된 scheduling이다. 즉, process사이의 context switching이 가능할 때만 RR방식을 이용한다.
- Time quantam(time slice) 라고 하는 시간을 할당량을 10~100ms정도 정의한다.
- ready queue는 원형으로 동작한다.
RR에는 두 가지 경우가 존재하는데
- process의 CPU burst가 TQ보다 짧은 경우
- process가 셀프로 CPU를 방출
- scheduler는 ready queue에 있던 다음 process를 진행
- process의 CPU burst가 TQ보다 긴 경우
- 시간초과되면 OS에서 interrupt
- Context switching
- 실행하던 process는 ready queue의 tail로 가서 다시 순서를 기다린다.
이렇게 실행된다. RR의 경우, average waiting time을 줄인다는 장점이 있다.
근데, Time quantum 설정이 중요하다. 너무 커도 안되고, 작아도 안 된다.
context switching시간보다 time quantum이 더 적다면 process가 아예 수행되지 않는다!! Turnaround 입장에서는 TQ가 큰게 좋고, reponse time 입장에서는 TQ가 작은게 좋다.
Priority Scheduling
priority는 우선순위가 가장 높은 process에게 CPU 권한을 할당한다.
preemptive, nonpreemptive 방식 둘 다 가능하다.
근데 문제점이 있다. 우선순위가 낮은 process는 계쏙해서 밀린다. 그리고 우선순위가 같으면 RR 병행한다.
Multilevel Queue Scheduling
multiple queue를 이용하여 multi level schedulig을 한다. 그러니까, ready queue를 다수의 별도 queue로 분류하여 수행하는 방식이다.
그래서 queue사이의 scheduling과 각 queue간의 scheduling이 둘 다 있다.
각각의 queue 내부에서는 RR을 쓸 수도, FCFS를 쓸 수도 있다.
이 위에있는 건, priority queue보다도 절대적인 우선순위를 가진다. real-time process, system process의 queue가 비어있지 않는 이상, interactive process는 실행될 수 없다. 뭐 이런식?
Multilevel Feedback Queue Scheduling
일단 multilevel queue에서는 process의 queue간 이동이 불가능했었다.
근데 여기서는 process들을 CPU burst 성격에 따라 구분한다. 어떤 프로세스가 CPU 시간을 너무 많이 사용하면, 낮은 우선순위의 큐로 이동되고, 입/출력 중심 프로세스와 대화형 프로세스들을 높은 우선순위 큐로 이동시킨다. 만약에 낮은 우선순위의 큐에서 너무 오래 대기하는 프로세스가 있다면, 높은 우선순위의 큐로 이동시킨다.
multilevel feedback queue scheduling은 다양한 parameter가 있다.
Thread Scheduling
이번에는 thread를 중심으로 scheduling을 살펴보자. user-level과 kernel-level thread의 차이는 어떻게 스케줄 되느냐에 있다. Many-to-one과 many-to-many 모델을 구현
Contention Scope(경쟁범위)
- Process-contention scope(PCS):
Many-to-one과 many-to-many 모델을 구현하는 시스템에서, thread library가 user-level thread를 가용한 LWP(Light Weight Process)상에서 스케줄링을 함.
이 구조는 동일한 process에 속한 thread 사이에서 CPU를 경쟁함
즉, user-level thread는 thread library가 사용이 가능한 LWP에 user-level thread를 schduling하는 것이고, PCS는 동일한 프로세스 범위에서 process 내부의 thread들이 CPU를 할당받기 위해 경쟁하는 것이다.
- System-contention scope(SCS):
실제로 CPU 상에서 실행되기 위해서, OS가 kernel thread를 물리적인 CPU로 스켖루링 하는 것이 필요함.
CPU상에 어떤 kernel thread를 스케줄하기 위해 결정하기 위해서 SCS를 사용함@!
Pthread Scheduling
- PTHREAD_SCOPE_PROCESS: PCS scheduling을 사용하여 thread scheduling
- PTHREAD_SCOPE_SYSTEM: SCS scheduling을 사용하여 thread scheduling
#include <pthread.h>
#include <stdio.h>
#define NUM THREADS 5
int main(int argc, char *argv[])
{
int i, scope;
pthread t tid[NUM THREADS];
pthread attr t attr;
/* get the default attributes */
pthread attr init(&attr);
/* first inquire on the current scope */
if (pthread attr getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope∖n");
else {
if (scope == PTHREAD SCOPE PROCESS)
printf("PTHREAD SCOPE PROCESS");
else if (scope == PTHREAD SCOPE SYSTEM)
printf("PTHREAD SCOPE SYSTEM");
else
fprintf(stderr, "Illegal scope value.∖n");
}
/* set the scheduling algorithm to PCS or SCS */
pthread attr setscope(&attr, PTHREAD SCOPE SYSTEM);
/* create the threads */
for (i = 0; i < NUM THREADS; i++)
pthread create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM THREADS; i++)
pthread join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread exit(0);
}
Multiprocessor Scheduling
multiprocessor는 아무래도 multi이다보니 schedulig이 더 복잡하다. Multiprocessor scheduling은 2가지 방법이 존재한다.
Multicore Precessors
- Asymmetric Multiprocessing
하나의 processor를 일명 master server로 지정하고, 모든 스케줄링 결과, 입/출력 처리, 다른 시스템 이동을 관리한다. 그리고 나머지 processor들은 그냥 user code만을 수행한다.
자료공유의 필요성을 배제하기 때문에 간단하다. 근데 master server에 시스템 부하 올 수도?
- Symmetric multiprocessing(SMP)
각각의 processor가 self-scheduling을 한다.! 여기서도 두개의 전략이 나뉘는데,
- 모든 thread가 ready queue 공통으로 사용→ possible race condition
- 각각의 proessor가 독립적인 ready queue → load balancing algorithm
다만 주의 할 점은 여러개의 processor가 공통 자료구조에 접근하여 갱신하면 스케줄러는 신중하게 프로그램되어야 하고,
두 processor가 같은 process를 선택하지 않도록 해야하고,
process 들이 queue에서 사라지지 않도록 보장해야 한다.
SMP system을 가진 multicore processor는 multichip에 비해 빠르고, power를 덜 소비한다.
memory stall:
multithreaded processing cores:
이 부분은 잘 이해가 안 가니까 다시 보자. 일단 그림만 첨부해놓겠따.
chip multithreading(CMT) : 하드웨어적으로 여러개의 thread를 실행할 수 있도록 하는 것
이거 보면 process는 4개의 core에 thread가 각 2개씩 있는 거지만, OS 관점에서는 8개의 core로 보인다!!!!!
- 하나의 core에서 multithreading을 하는거
- Coarse grained: long-latency event가 발생할 떄 까지 실행
- Pipeline flushing → high cost of thread switching
- Fine-grained(interleaved): instruction cycle 단위로 switching함
- Concurrent, not parallel
- holding multiple threads
- sharing hardware for execution
- two levels of scheduling
- share-aware algorithm(동시에 실행해야할 thread들은 서로 다른 core에 할당)
- Concurrent, not parallel
- No pipeline flushing → small cost; extra logic required
Load Balancing
SMP 시스템의 모든 processor사이에 workload가 고르게 배분되도록 시도하는 것! 두가지 방식이 존재한다.
- Push migration
특정 task가 주기적으로 processor의 workload를 검사하고, 만일 불균형한 상태라면 workload가 적은 처리기로 process를 push하여 workload를 분배하는 방식
- Pull migration
ide한 processor가 직접 waiting task를 가져오는 방식
Balanced load를 위해서는 모든 queue의 thread수를 비슷하게 유지하거나 또는, 모든 queue에 동등한 priority를 부여하는 것이 있따.
Processor Affinity
SMP 시스템이 processor간 migration을 피하고 대신 같은 processor에서 process를 실행시키려고 하는 현상이다.
processor affinity가 왜 발생하는가?
만약에 processor간의 migration이 발생하면, cache memory를 삭제하고, migrate한 processor에 다시 cache memory를 작성하게 되는데, 이 작업이 비용이 많이 든다.
processor affinity도 두가지 종료가 있다.
- Soft Affinity: 동일한 Processor에서 process를 실행시키려고 노력하는 정책을 가지고 있지만 보장하지는 않음
- Hard Affinity: system call을 이용해 실행할 수 있는부분집합 processor를 만들어놓고, 그 안에서 process를 할당함
<aside> ▶️ Load balancing과 processor affinity 사이에 counteraction이 존재함!!
</aside>
HMP(Heterogeneous Multiprocessing)
'OS' 카테고리의 다른 글
| [운영체제] Threads & Concurrency (2) (1) | 2024.04.18 |
|---|---|
| [운영체제] Threads & Concurrency (0) | 2024.04.11 |
| [운영체제] Processes(2) (2) | 2024.04.03 |
| [운영체제] Processes (0) | 2024.04.01 |
| [운영체제] OS 구조 (0) | 2024.04.01 |